A Unified Audio-Visual Learning Framework for Localization, Separation, and Recognition
Abstract
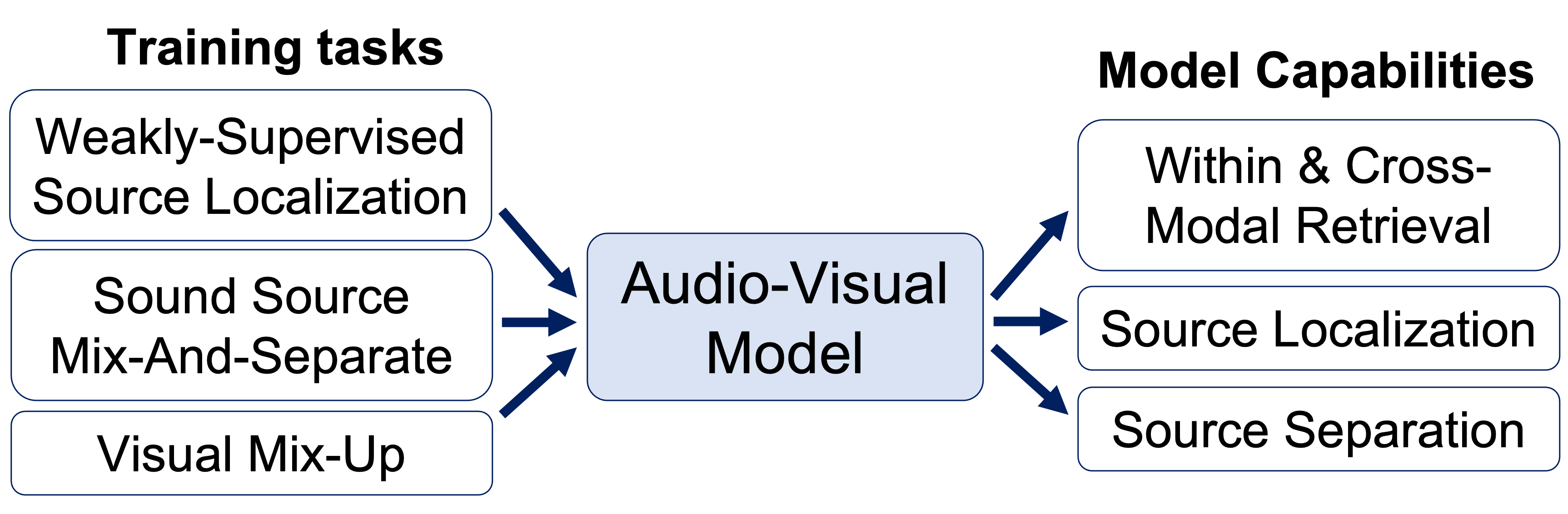
The ability to accurately recognize, localize and separate sound sources is fundamental to any audio-visual perception task. Historically, these abilities were tackled separately, with several methods developed independently for each task. However, given the interconnected nature of source localization, separation, and recognition, independent models are likely to yield suboptimal performance as they fail to capture the interdependence between these tasks. To address this problem, we propose a unified audio-visual learning framework (dubbed OneAVM) that integrates audio and visual cues for joint localization, separation, and recognition. OneAVM comprises a shared audio-visual encoder and task-specific decoders trained with three objectives. The first objective aligns audio and visual representations through a localized audio-visual correspondence loss. The second tackles visual source separation using a traditional mix-and-separate framework. Finally, the third objective reinforces visual feature separation and localization by mixing images in pixel space and aligning their representations with those of all corresponding sound sources. Extensive experiments on MUSIC, VGG-Instruments, VGGMusic, and VGGSound datasets demonstrate the effectiveness of OneAVM for all three tasks, audiovisual source localization, separation, and nearest neighbor recognition, and empirically demonstrate a strong positive transfer between them.
Published at: International Conference on Machine Learning (ICML), Honolulu, 2023.
Bibtex
@InProceedings{mo2022_slavc,
title={A Unified Audio-Visual Learning Framework for Localization, Separation, and Recognition},
author={Shentong Mo, Pedro Morgado},
booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML)},
year={2023}
}