Semantically Consistent Regularization for Zero-Shot Recognition
Abstract
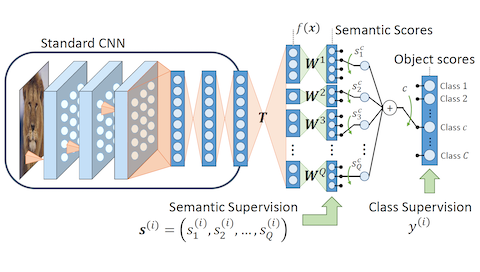
The role of semantics in zero-shot learning is considered. The effectiveness of previous approaches is analyzed according to the form of supervision provided. While some learn semantics independently, others only supervise the semantic subspace explained by training classes. Thus, the former is able to constrain the whole space but lacks the ability to model semantic correlations. The latter addresses this issue but leaves part of the semantic space unsupervised. This complementarity is exploited in a new convolutional neural network (CNN) framework, which proposes the use of semantics as constraints for recognition.Although a CNN trained for classification has no transfer ability, this can be encouraged by learning an hidden semantic layer together with a semantic code for classification. Two forms of semantic constraints are then introduced. The first is a loss-based regularizer that introduces a generalization constraint on each semantic predictor. The second is a codeword regularizer that favors semantic-to-class mappings consistent with prior semantic knowledge while allowing these to be learned from data. Significant improvements over the state-of-the-art are achieved on several datasets.
Published at: Conf. on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2017.
Bibtex
@inproceedings{morgadoCVPR17,
title={Semantically Consistent Regularization for Zero-Shot Recognition},
author={Pedro Morgado and Nuno Vasconcelos},
booktitle={Computer Vision and Pattern Recognition (CVPR), IEEE/CVF Conf.~on},
year={2017},
organization={IEEE}
}